
AIによるモーション生成技術が急速に進化する中、NVIDIAのSpatial Intelligence Labが新たなAIモデル「Kimodo」を公開しました。700時間分にも及ぶ大規模な光学式モーションキャプチャデータから学習したこのモデルは、テキストを入力するだけで高品質な3Dモーションを生成できます。さらに身体の動きをより細かくコントロールできる複数の制約機能を備えており、モデルとウェイトはオープンソースとして公開、条件を満たせば商用利用も可能となっています。
本記事では、Kimodoがどのようなモデルなのか、どのような技術が使われているのか、そしてどのような場面で活用できるのかを紹介します。
Kimodo 概要
| 項目 | 内容 |
| モデル名 | Kimodo(Kinematic Motion Diffusion Model) |
| 開発元 | NVIDIA Spatial Intelligence Lab |
| 学習データ | 光学式モーションキャプチャデータ 700時間分 |
| 主な入力方法 | テキストプロンプト、フルボディキーフレーム、エンドエフェクタ制約、2Dウェイポイント・パスなど |
| 対応スケルトン | SOMA(デジタルヒューマン向け)、Unitree G1(ヒューマノイドロボット向け)、SMPL-X |
| 対応出力形式 | NPZ、CSV(G1スケルトン)、BVH(SOMAスケルトンのみ)、MuJoCo対応形式など |
| ライセンス | NVIDIA Open Model License(条件付き商用利用可)※SMPL-Xモデルのみ研究用途限定 |
| 公開先 | GitHub / Hugging Face |
| プロジェクトページ | https://research.nvidia.com/labs/sil/projects/kimodo/ |
Kimodoとは?
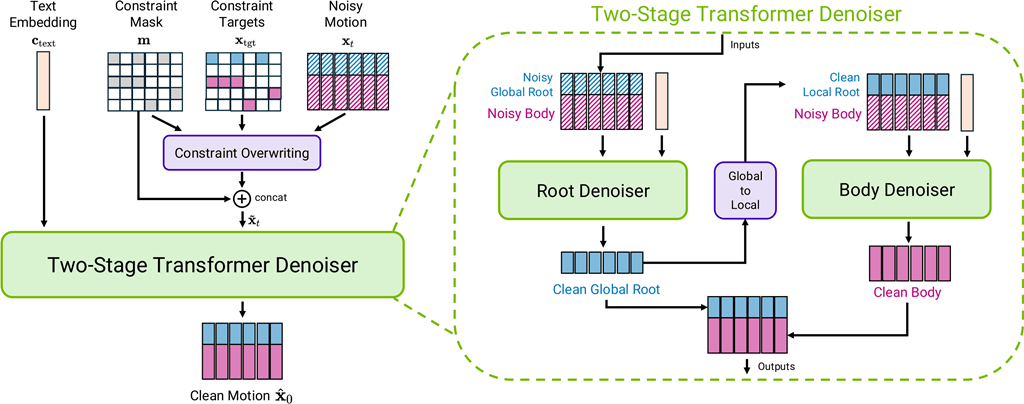
Kimodoは、「Kinematic Motion Diffusion Model(運動学的モーション拡散モデル)」の略称を持つAIモデルです。「歩きながら手を振る」「ダンスをする」といったテキストプロンプトを入力するだけで、人間の動作を高精度に生成することができます。
モーション生成AIはこれまでも様々なものが登場してきましたが、Kimodoの大きな特徴は「テキストによる大まかな指示」と「細かな動きの制御」を組み合わせられる点にあります。テキストプロンプトに加えて、フルボディのキーフレーム指定・手足など特定の部位の位置や回転の制御・空間内の移動経路の指定など、複数の入力方法を組み合わせることで、意図した通りのモーションをより正確に生成することが可能です。
また、学習に使用されたデータは700時間分にも及ぶ光学式モーションキャプチャデータです。光学式はモーションキャプチャの中でも特に精度が高いとされる手法であり、こうした高品質なデータを大量に学習することで、Kimodoは自然で滑らかな動作生成を実現しています。
従来のAIモーション生成の課題と、Kimodoの解決策
AIによるモーション生成においてこれまで課題となっていたのが、「フットスケート」と呼ばれる現象です。フットスケートとは、キャラクターが移動しているにもかかわらず、足が地面に対して滑ってしまう不自然な動きのことです。キャラクターの移動と手足の動きを同時に計算する従来の手法では、この現象や不自然なブレが生じやすい構造的な問題がありました。
Kimodoはこの課題を解決するために、「2段階デノイザーアーキテクチャ(Two-stage Denoiser Architecture)」という仕組みを採用しています。これは、動きの計算を「空間全体における身体の移動(Root)」と「手足など身体各部の細かな動き(Body)」の2つに分けて処理するアプローチです。まずRootデノイザーが全身の移動経路を予測し、その結果をローカル座標に変換したうえでBodyデノイザーに渡すことで、自然な重心の動きを保ちながら各部位の細かな動きを生成します。
この仕組みにより、指定した経路を正確になぞりながらも物理法則に反しない自然な動作を生成することに成功しています。フットスケートや不自然なブレといった従来の問題が大きく改善されており、後処理としてフットスケートの補正も行われます。
Kimodoの主な制御方法
Kimodoでは、目的に応じて複数の入力方法を組み合わせながらモーションを生成することができます。
テキストプロンプト
「歩く」「ダンスをする」「手を振る」といったテキストを入力することで、AIが対応するモーションを生成します。
なお、プロンプトは英語での記述のみ対応しており、動作の具体性が高いほど生成品質が向上する傾向があります。「歩きながら手を振る」といった複数の動作を組み合わせた指示や、時系列に沿って複数のプロンプトをつなぐシーケンス指定にも対応しています。
フルボディキーフレーム制約
特定のフレームで全身の関節位置を指定する制約です。
例えば「この瞬間にこのポーズを取る」といった指定が可能で、振り付けの決めポーズや特定のアクションの頂点を正確に再現したい場合に有効です。制約はビジュアライザ上で赤いスケルトンとして表示されるため、視覚的に確認しながら調整できます。
エンドエフェクタ制約
手や足など身体の末端部位(エンドエフェクタ)の位置と回転を個別に指定できる制約です。
「右手だけをここに固定する」「両足の接地位置を指定する」といった使い方が可能で、物体を掴む動作や特定の場所への接触を表現したい場合に活用できます。手のみ・足のみ・手足両方など、組み合わせも柔軟に設定できます。
2Dウェイポイント・パス指定
空間内の移動経路を2Dで指定する入力方法です。
経路上にウェイポイント(通過点)を置く方法と、密なパス(連続した経路)を描画する方法の2種類があります。「このルートを通って移動する」という経路を指定することで、ステージ上の動線管理や特定の場所への移動を正確に再現することができます。ダンスの振り付けとウェイポイントを組み合わせた制御も可能です。
利用可能なモデルの種類
Kimodoには用途に合わせて複数のモデルが用意されています。なお、2026年4月にはSOMAスケルトン向けのv1.1モデルが追加リリースされ、品質の向上とベンチマーク対応が行われています。
| モデル名 | 対応スケルトン | 学習データ | 主な用途 | ライセンス |
| Kimodo-SOMA-RP-v1.1 | SOMA | 700時間 | デジタルヒューマン・アニメーション(最新版) | NVIDIA Open Model(商用利用可) |
| Kimodo-SOMA-SEED-v1.1 | SOMA | 288時間 | 軽量な基本動作の生成(最新版) | NVIDIA Open Model(商用利用可) |
| Kimodo-G1-RP-v1 | Unitree G1 | 700時間 | ヒューマノイドロボットのモーション生成 | NVIDIA Open Model(商用利用可) |
| Kimodo-G1-SEED-v1 | Unitree G1 | 288時間 | 軽量な基本動作の生成 | NVIDIA Open Model(商用利用可) |
| Kimodo-SMPLX-RP-v1 | SMPL-X | 700時間 | 人体モーション研究・VR/AR | NVIDIA R&D Model(研究用途限定) |
全モデルはHugging Faceから取得でき、CLIやデモの初回実行時に自動でダウンロードされます。なお、コードベースはApache-2.0ライセンスですが、モデルのチェックポイントはモデルごとに異なるライセンスが適用されています。商用利用を検討している場合は、各Hugging Faceページのライセンス表記を事前に確認することを推奨します。
活用が期待される分野

Kimodoは、3Dコンテンツ制作に関わる幅広い分野での活用が期待されています。
ゲーム・映像制作
キャラクターのモーション制作は、ゲームや映像制作において多くの時間とコストがかかる工程のひとつです。
Kimodoを活用することで、テキストで指示するだけで自然なモーションのベースを素早く生成し、制作の初速を高めることができます。歩行・ダンス・ジェスチャー・物体操作など多様な動作に対応しており、生成したモーションをベースにアニメーターが細部を調整するワークフローとの相性も良いでしょう。
VTuber・バーチャルプロダクション
ダンスや演技のモーションをAIで生成・調整するワークフローへの応用も考えられます。
スタジオや機材を用意しなくてもモーションデータを生成できる点は個人クリエイターにとっても魅力的です。SOMAスケルトン向けモデルを使えばBVH形式での書き出しが可能なため、既存の3DCGツールとの連携もスムーズに行えます。
ロボティクス・研究開発
Kimodoはロボティクス分野での活用も強く意識して設計されており、ヒューマノイドロボット「Unitree G1」のスケルトンに対応したモデルも用意されています。
生成したモーションデータをNVIDIA Isaac SimやMuJoCoにインポートすることで物理シミュレーション上での検証が可能なほか、強化学習の訓練データとしての活用も想定されています。また「GMR(General Motion Retargeting)」を使うことで、生成したモーションを他のロボットに転用することもできます。
動作環境について
Kimodoはテキスト埋め込みモデルのサイズにより、GPUのみで動作させる場合は約17GBのVRAMを必要とします。
これはテキストエンコーダとして大規模言語モデルが使われているためです。ただし、テキストエンコーダの処理をCPU側で行うオプション(TEXT_ENCODER_DEVICE=cpu)を使えば、必要なVRAMを3GB未満に抑えることができます。その場合は処理がやや遅くなりますが、VRAMの少ない環境でも利用可能です。
動作確認が取れているGPUは、GeForce RTX 3090・RTX 4090・NVIDIA A100などで、Windowsでも動作するとされています。
生成速度はテキストエンコーダサービスを常駐させた状態で1回あたり約7〜9秒です(拡散ステップ100回分)。現時点ではリアルタイム生成には対応していませんが、事前生成したモーションデータを制作に組み込むワークフローであれば十分実用的な速度といえます。
オープンソースでの公開について
Kimodoはオープンソースのプロジェクトとして公開されており、Hugging FaceおよびGitHubからモデルの重みデータとソースコードを誰でも無償で取得することができます。
ライセンスは「NVIDIA Open Model License」が適用されており、条件を満たせば商用利用や派生モデルの作成・配布も許可されています(SMPL-Xスケルトン向けモデルを除く)。
Hugging Face上ではオンラインデモも公開されており、実際の動作をブラウザ上で試すことができます。
また、ウェブベースのインタラクティブデモ(kimodo_demo)をローカルで起動することも可能で、タイムライン上でキーフレームや制約を視覚的に配置しながらモーションを生成する直感的なインターフェースが用意されています。
- プロジェクトページ:https://research.nvidia.com/labs/sil/projects/kimodo/
- GitHub:https://github.com/nv-tlabs/kimodo
- Hugging Face:https://huggingface.co/collections/nvidia/kimodo-v1
- オンラインデモ:https://huggingface.co/spaces/nvidia/Kimodo
まとめ
今回は、NVIDIAが公開した新AIモデル「Kimodo」について紹介しました。
700時間分の光学式モーションキャプチャデータから学習したKimodoは、テキストプロンプトによる直感的な操作に加え、フルボディキーフレーム・エンドエフェクタ制約・ウェイポイントといった細かな制御手段を組み合わせられる点が大きな特徴です。
2段階デノイザーアーキテクチャによってフットスケートなどの従来の課題を克服しており、歩行・ダンス・ジェスチャーといった多様な動作を高品質に生成できます。
オープンソースで公開されており、ゲーム・映像制作やVTuberコンテンツ、ロボティクスなど、3Dモーションに関わるさまざまな分野での活用が広がっていくことが注目されます。
まずはHugging Face上のオンラインデモから試してみてはいかがでしょうか。